 Huggingface
Huggingface
News
- 9-18-2025: AstroVisBench has been accepted into the NeurIPS 2025 Benchmark and Datasets Track!
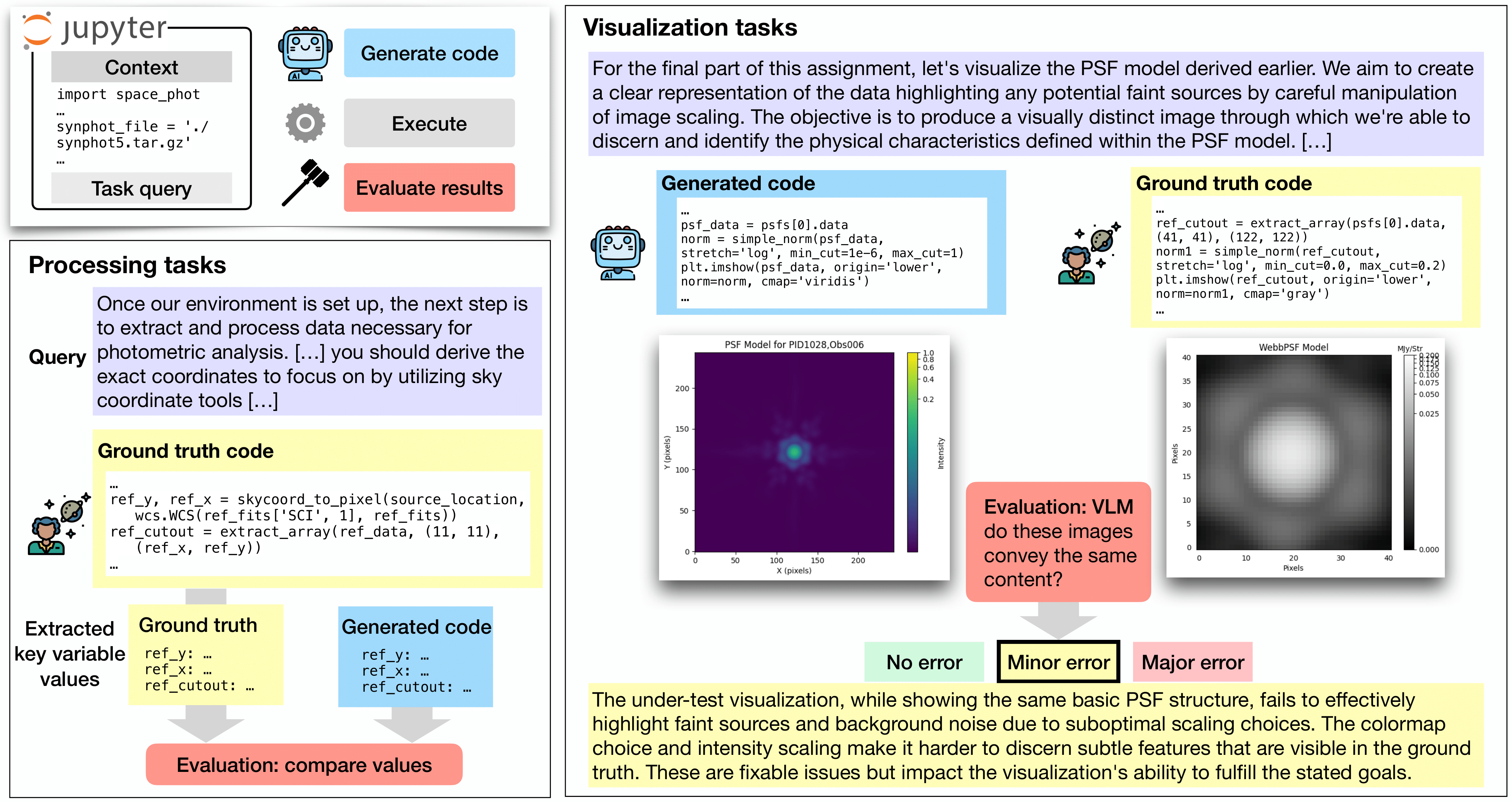
We introduce AstroVisBench, the first benchmark for both scientific computing and visualization in the astronomy domain. AstroVisBench judges a language model’s ability to both:
- Create astronomy-specific workflows to process and analyze data (Processing)
- Visualize the results of these workflows through complex plots (Visualization)
We use the following metrics evaluate LLMs using this benchmark along these dimensions:
- Processing No Error %: This is the percent of processing task responses that executed without crashing. (Higher is better)
- VIscore: This is the Variable Inspection score, indicating how well successfully executed generated code is able to create data products that match those created by the ground truth. (Higher is better)
- Visualization No Error %: This is the percent of visualization task responses that executed without crashing. (Higher is better)
- VisFail %: This is the percent of visualization task responses that failed to follow instructions and generate only one visualization. (Lower is better)
- Visualization Errors (CorrectV, MiE, MaE): This is the breakdown of Correct/No Errors, Minor Errors, and Major Errors in the set of LLM-generated visualizations as determined through our automated LLM-as-a-judge method. (Higher CorrectV is better)
We present the results of evaluating several LLMs on AstroVisBench below in an interactive leaderboard. If you would like to test your models on this benchmark, you can find the code to execute and evaluate model responses in our GitHub Repository .
Citation
Please cite our paper if you found our work to be useful in your work:
@misc{joseph2025astrovisbenchcodebenchmarkscientific,
title={AstroVisBench: A Code Benchmark for Scientific Computing and Visualization in Astronomy},
author={Sebastian Antony Joseph and Syed Murtaza Husain and Stella S. R. Offner and Stéphanie Juneau and Paul Torrey and Adam S. Bolton and Juan P. Farias and Niall Gaffney and Greg Durrett and Junyi Jessy Li},
year={2025},
eprint={2505.20538},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.20538},
}
Leaderboard
Models
Metrics
Select models
Select Metrics
| Model - | NoErr(P) % - | VIscore - | NoErr(V) % - | CorrectV % - | VisFail % - | MiE % - | MaE % - |
|---|